
Routing Packets
Routing Information Protocol version 2 (RIPv2) is considered an older, but still useful in some cases, protocol for dynamically exploring other networks, exchanging routing information between devices, and establishing connections between networks. Routing protocols like RIPv2 don’t directly send packets across the network. They simply establish the best path to get those packets from source to destination.
RIPv2 is one of several possible routing protocols, each of which are suitable for different types of networks. Some routing protocols work well for setting static routes small networks that don’t change much. Others work well for large networks where portable devices can move from one subnet to another and obtain new IP addresses to suit. The speed at which convergence occurs is a factor in large, dynamic networks. Convergence occurs when routers on a network agree on optimal routes for getting packets to their destination. When convergence takes a long time, packets can bog down a network with routing loops, dropped connections and intermittent packet loss.
Administrative Distance
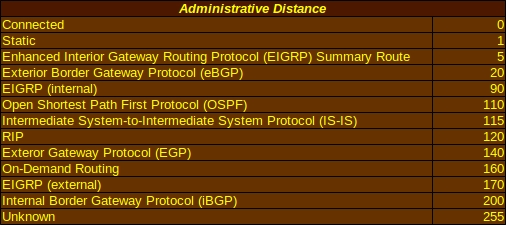
Administrative distance is used to determine the reliability of the source of routing information. Each source is given an integer value between 0 and 255, with 0 indicating the highest level of reliability and 255 being the lowest. Connected interfaces and static routes, with default administrative distances of 0 and 1 respectively, are considered the most reliable and will be used first whenever possible. The router will use only the administrative distance table stored in its memory to determine the reliability of any source of routing information. For instance, RIPv2 has a default value of 120 and will be used after connected interfaces, static routes and a few protocols that the router considers more reliable, but before On-Demand Routing with a distance of 160 and a route from an unknown source with a distance of 255. Administrative distance is one of the pieces of information displayed when the show ip protocols command is used on a Cisco IOS.
Metrics
Routing protocol algorithms assign numerical values called metrics to specific routes. These metrics are used to set up priorities for routes detected by the protocol. Each route and its metric value are added to the routing table. Like administrative distances, routes with low metric values will be used before routes with high metric values.
Each routing protocol algorithm uses its own set of variables for calculating the metric. Some older and less advanced routing protocol algorithms might only use a single variable, such as bandwidth or reliability, and don’t necessarily choose what humans would consider the “best path.” For instance, RIP might choose a path with only two hops and the heinously slow speed of 64Kbps.
The algorithms of more advanced routing protocols use multiple variables. This helps to reduce the problem of routers using the slow connection with two hops when there is a fast GigabitEthernet connection with four hops available.
Variables used by these algorithms can include:
- Bandwidth: This is the amount of data that can travel over a medium over any given period of time and is used by the routing protocols OSPF and EIGRP in their metric calculations. All other things being equal, an algorithm could prefer GigabitEthernet over FastEthernet because the GigabitEthernet link is faster. This can be adjusted simply be adjusting the speed of the interfaces. You can trick the algorithm into seeing the two interfaces’ bandwidth capacity as exactly the same by accessing the FastEthernet interface and using the command bandwidth 1000000 interface. This does not actually mean that FastEthernet can handle the same speeds as GigabitEthernet, so be cautious about using this command.
- Cost: This refers to the actual monetary cost of using any particular link and can be used by companies that prefer to use private links rather than public ones to save money. Certain protocols such as Intermediate System-to-Intermediate System (IS-IS) have an optional metric that measures the cost of link usage.
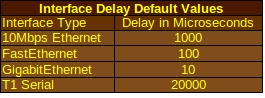
- Delay: This refers to the actual time it takes for a data packet to travel over a network and is usually measured in microseconds. EIGRP is one protocol that uses the delay value in its calculations. The value that the algorithm actually sees can be adjusted using the command delay interface <delay value in microseconds>. This does not reflect the actual amount of delay but can be used if you want the algorithm to prefer a particular route.
- Load: This refers to the workload of any given resource on a computer network. In routing terms, the load is the amount of work that a particular router interface performs and is given as a fraction of 255. A load of 255/255 means that the interface is practically being flooded with packets, while a load of 128/255 means that it is working at about 50% capacity. This fraction is calculated as the average load over a period of 5 minutes by default. Protocols like EIGRP use it in their metric calculations.
- Path Length: This refers to the distance that a packet has already traveled over the network. RIP calculates this distance as the number of hops that a packet has already taken from device to device. BGP counts the number of autonomous systems between the packet’s current router and its destination network.
- Reliability: This refers to the dependability of interfaces available to the local router and is also given as a fraction of 255, with 255/255 being the most reliable. This is calculated as an average over periods of five minutes.
- Stability: While not strictly a metric variable, algorithms should know what to do when unexpected events occur. Some algorithms are better at handling a failed network device than others and that affects their administrative distance.
- Prefix Matching: When deciding which route out of a routing table to actually use, Cisco routers typically use the longest and most specific routing table entry when choosing the route used to forward traffic, regardless of the administrative distance of the route source or the routing protocol metric. Less specific entries, such as summary addresses, will be chosen only if the longer ones are unavailable or another factor prevents them from being used right away.
Building An IP Routing Table
A routing table, also called a Routing Information Base (RIB), provides information about remote networks that would otherwise be unavailable to a router. This information is used by the router as part of determining which route will be used to forward data to its destination. Factors that help determine which routes are actually placed into a routing table include administrative distance, routing protocol metric determined by the preferred routing protocol, and the prefix length of each entry.
A route entry will be placed in the table if it does not currently exist or is more specific than a current entry. It won’t replace the current, less specific entry but may be placed in a slot that gives it a higher priority. If the route entry is the same as an existing one but came from a preferred source, it will replace the old entry. A static route that may have been manually configured by the network administrator will replace the exact same route that has been arrived at using RIP if all the default administrative distances are in place. If a routing protocol adds an entry that is the same as the existing one that was arrived at by the same protocol, but the metric is different on the new route, it can:
- Discard the new route if its metric is higher than the existing route;
- Replace the existing route with the new route if the metric of the new route has a lower value; or
- Use both routes for load balancing if the metric are identical.
Routing Protocol Classes
Distance Vector routing protocols use a single one-dimensional vector when determining the best route along a network. One-dimensional vectors are directed quantities along a particular course. These vectors look a lot like number lines when drawn out in a human-readable form and pay more attention to how far a vector travels than the actual starting and ending point.
Distance vectors use distance in the form of the number of hops using the Bellman-Ford algorithm and periodically send out copies of their routing tables to nearby routers. On a large network, it is possible for resources to be flooded by many routers sending out their routing tables at the same time.
Distance vectors also use the “Counting to Infinity” characteristic to determine whether packets are undeliverable and prevent networks from becoming swamped with bad packets. In the early days of networking, many routing protocols built on the idea that a destination would be considered unreachable after a certain number of hops. This makes those early protocols unsuitable for very large networks that might require many hops to get the packets from one end of the network to the other.
The split horizon mechanism prevents Distance Vector protocols from sending information back out through the same interface that it arrived on. It makes for a good loop prevention mechanism but becomes a drawback on networks that rely on hubs and spokes. Poison reverse, also called route poisoning, is a variation of split horizon that allows networks to be advertised on the same interface that the information was originaly received, but also uses a metric of “unreachable” so that the receiving router doesn’t add them back into the routing table.
Hold-down timers prevent routers from trying to transmit over a network that’s down by telling it to wait a specified amount of time before accepting changes in the status of that specific network and suppress the advertising of inaccurate information. This helps to keep traffic from being lost without explanation.
This makes Distance Vector protocols better suited for small networks. RIP and IGRP are both Distance Vector protocols. EIGRP is a kind of hybrid Distance Vector/Link State protocol that uses elements of both.
Link State Routing Protocols determine best paths using the Shortest Path First (SPF). These protocols require that all routers on a network share identical database information via a database exchange process. The algorithms used create shortest-path trees to all hosts that the router knows about or along the network backbone.
Link State protocols allow for better scalability than Distance Vector by logically grouping all routers in a specific “area.” This allows routers on large networks to operate in a more efficient manner and create databases composed of data about the entire topology of the network from their own point of view (i.e. routers in a particular logical area are the base of the hierarchical structure they create.) Weaknesses such as routing loops don’t exist in Link State protocols, eliminating the need for Distance Vector solutions such as split horizon.
Link State protocols routinely send out updates that include information on attached interfaces, metrics and relevant variables to other routers. These updates are referred to as Link State Advertisements and Link State Packets. As each router receives this information, it builds the Link State Database (LSDB) and calculates the SPF algorithm to determine the best paths for data.
Link State routing protocols avoid flooding large networks in the same way Distance Vector protocols can by sending out incremental updates whenever a change in the network is detected. The incremental update only informs other routers of the actual change made and allows routers to respond much faster when updating their information after the network configuration has been altered.
Static Routing
Network administrators use static routing to set routes that will only change if they manually adjust the routes to suit changes on a network. Static routes have a low administrative distance value, so it will be used before routing protocols come into play. This has the strength of saving network resources that would have been used by routing protocols to calculate what they think is the best route and update all other routers with new information.
Cons of static routing include a greater maintenance overhead. When routes are added or changed, all routers will have to be reconfigured manually. There is also the greater potential of incorrect routes being added to the routing table. If any particular route goes down, static routing will fail to detect it and continue sending traffic along the down route. It is possible to combine static routing and dynamic routing to suit the needs of your network.
Static routes can be used to configure the next hop that packets need to take towards their destination using two methods:
- IP address: When you know the IP address that the packet will be routed to on its way to a particular destination, a typical routing configuration command will look like ip route 192.168.1.0 255.255.255.0 172.16.1.2 This tells the router to send packets bound for a destination with an IP address of 192.168.1.0 and subnet mask of 255.255.255.0 to the device with an address of 172.16.1.2.
- Interface: In some cases, a packet’s next hop will take it to an external network or to a network with an IP address that could change in the future. In that case, your router should be set to use a specific interface with a command like ip route 192.168.1.0 255.255.255.0 s0/0. This tells the router to send traffic bound for an address of 192.168.1.0 with a subnet mask of 255.255.255.0 to its s0/0 interface.
You can also set a default route for traffic not listed in the routing table using the command ip route 0.0.0.0 0.0.0.0 s0/0. This directs packets meant for addresses not in the routing table along the s0/0 line.
Troubleshooting static routes can be done using the traceroute or tracert commands, depending on the OS you are using. These commands tell you the route that packets take towards any given destination and where they might be getting dropped.
Advanced Concepts for Networking Specialists


More Networking from eBay
[simple-rss feed=”http://rest.ebay.com/epn/v1/find/item.rss?keyword=Cisco+routers&categoryId1=58058&sortOrder=BestMatch&programid=1&campaignid=5337337555&toolid=10039&listingType1=All&lgeo=1&feedType=rss” limit=10]







